
1.1为什么数据挖掘
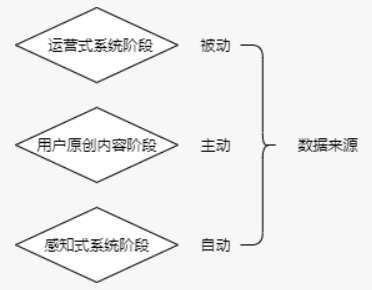
数据:数据是记录下来可以被鉴别的符号。它是最原始的素材,未被加工解释,没有回答特定的问题,没有任何意义。
信息:信息是已经被处理、具有逻辑关系的数据,是对数据的解释,这种信息对其接收者有意义。
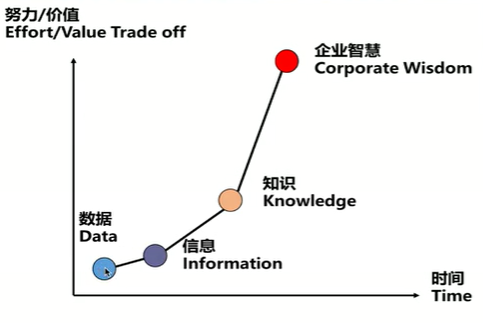
数据挖掘的定义
数据挖掘,通常也被称为数据知识发现(KDD),是自动或方便地提取模式,表示在大型数据库,数据仓库,Web,其他海量信息库或数据流中隐式存储或捕获的知识——Jiawei Han
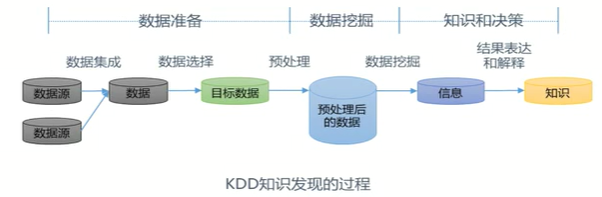
1.2数据挖掘的框架
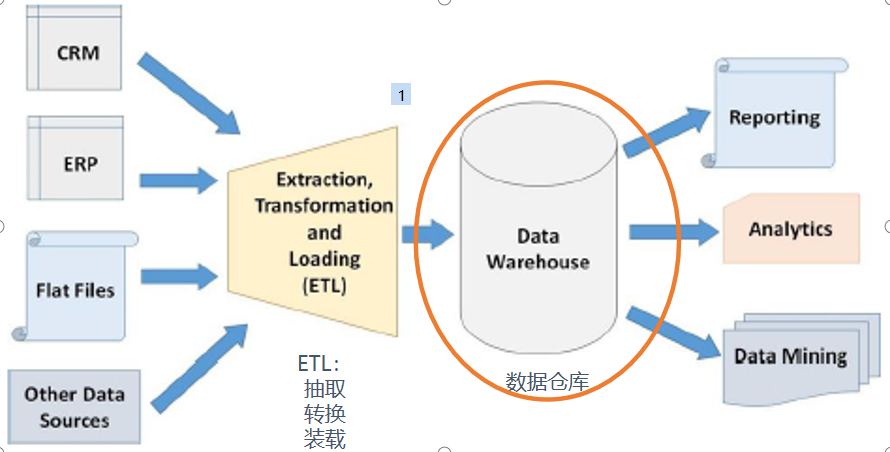
数据准备环节
CRM:客户关系管理
ERP:企业资源计划
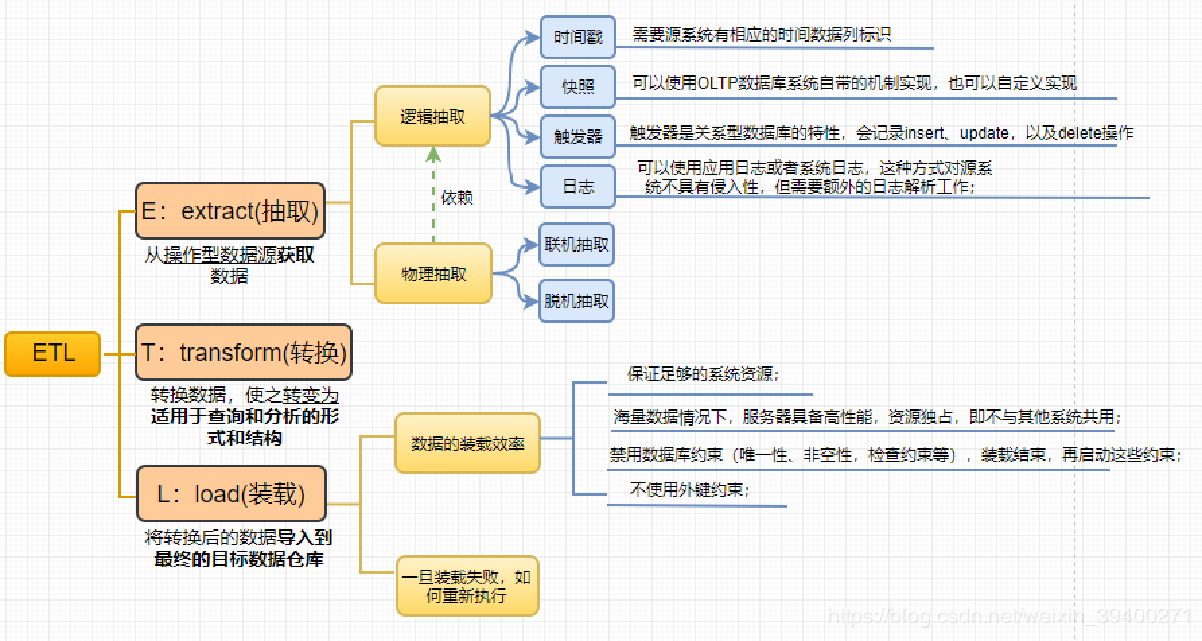
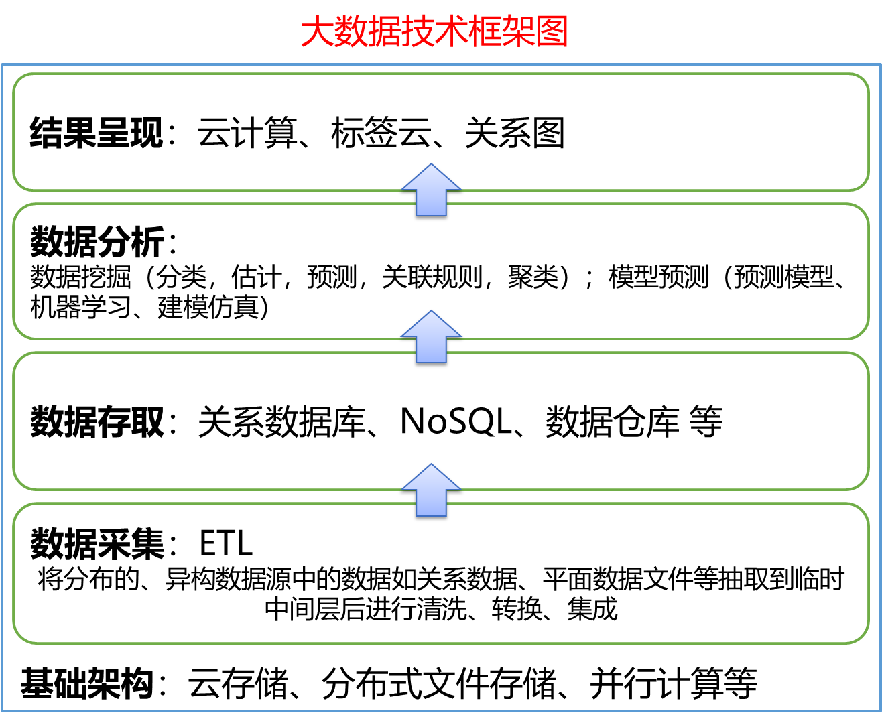
ETL:ETL负责将分布的、异构数据源中的数据如关系数据、平面数据文件等抽取到临时中间层进行清洗、转换、集成,最后加载到数据仓库中,成为联机分析处理(OLAP)、数据挖掘的基础。
E抽取:从操作型数据源获取数据
- 不可在源系统添加额外的逻辑;
- 不能增加源系统的工作负载;
T转换:转换数据,使之转变为适用于查询和分析的形式和结构
- 数据清洗cleansing:缺失数据、错误数据、重复数据等;
- 数据转换:数据类型、数据粒度、商务规则等;
L加载:将转换后的数据导入到最终的目标数据仓库
- 合理的业务模型设计:数据标准化,实现统一的编码、统一的分类和组织
- 加载的效率
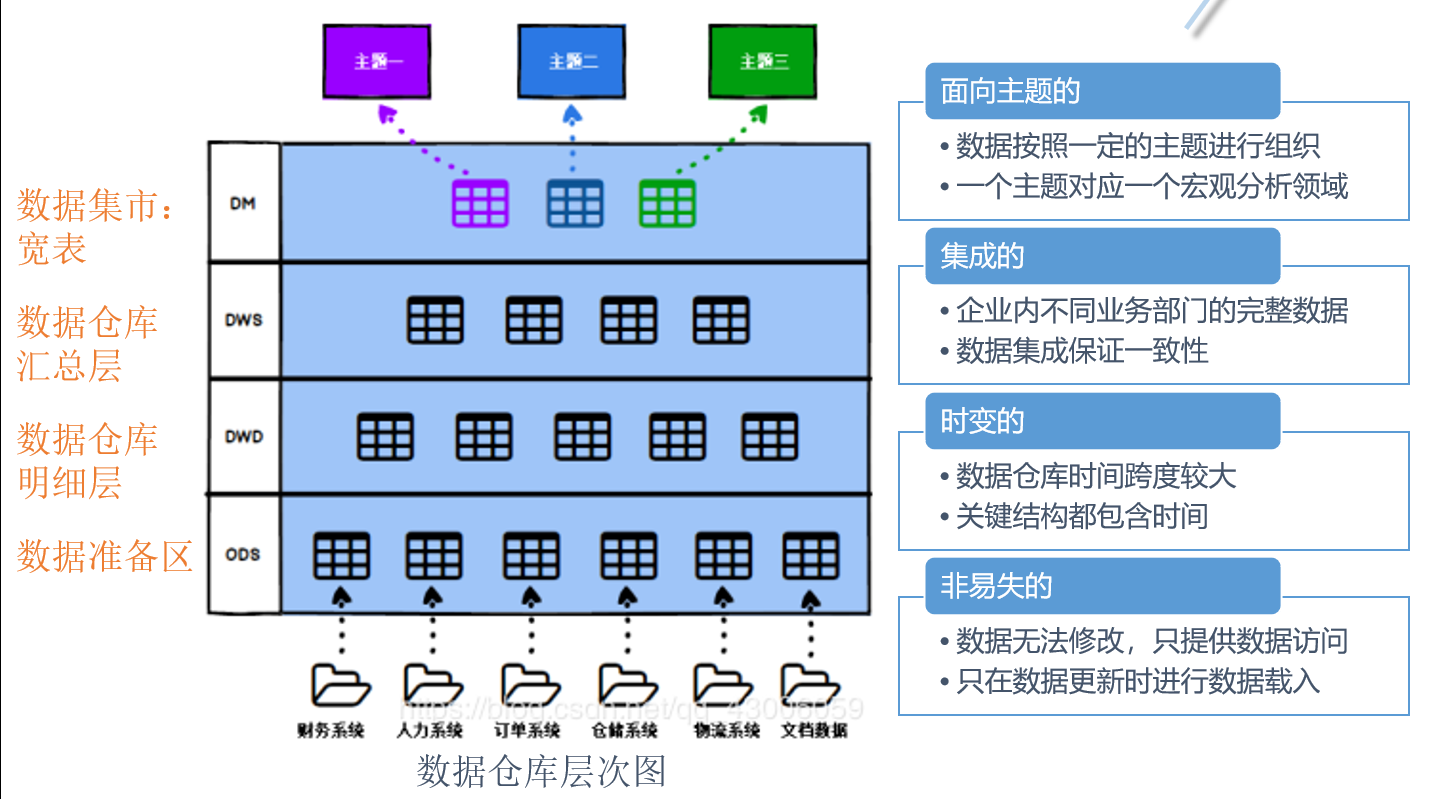
DB VS DW
DB(Database)数据库:数据库是一个按数据结构来存储和管理数据的计算机软件系统。
- 关系型数据库:Mysql,SqlServer等
- NoSQL数据库:MongoDB、Redis、Memcache等
DW(Data Warehouse)数据仓库:是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。
- Teradata、Snova、Greenplum等
关系型数据库
ACID特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
- A:A给B转账,如B账户操作失败,则交易失败,A和B都不修改
- C:A给B转账,无论是否操作成功,两者的账户余额之和不变
- I:对并发访问进行控制
- D:事务操作完成,则永久更改
非关系型数据库NoSQL
BASE约束:基本业务可用性(Basic Availability)、柔性状态(Soft state)、最终一致性(Eventual consistency)
- BA:系统在外界看来似乎总处于可用状态,只有落在故障节点的用户请求才会感知到系统不可用
- S:一个节点写入新数据后,不会立即更新集群其它节点,其他节点可能会读到旧数据
- E:在一段时间后,可以保证数据最终的一致性


数据预处理
- 数据清洗
- 数据集成
- 数据变换
- 特征选择
- 特征提取
- 数据相似性度量
- 数据可视化
1.3数据挖掘模型
深度学习:基于深度神经网络模型
机器学习:使用机器学习的方式达到智能
人工智能:使机器变得智能
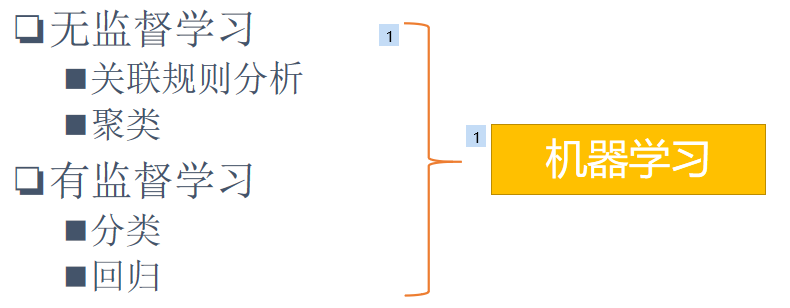
无监督学习
基于数据本身分析其中的规律
有监督学习
在指定结果变量的情况下分析其他变量与结果变量的关系
关联规则分析(无监督)
分析变量之间的相关性
聚类(无监督)
利用向量距离分析数据的分布
分类(有监督)
分析多变量与结果变量之间的映射关系(离散)
回归(有监督)
分析多变量与结果变量之间的映射关系(连续)
1.4数据挖掘常用的工具
传统的数据挖掘套件
- SAS Enterprise Miner 5.3
- SPSS Clementine 12
开源数据挖掘软件
- RapidMiner
- KNIME
- Weka
BI产品内置的数据挖掘软件
- SAP NetWear 7.0 Data Mining Workbench
- Oracle 11g Data Mining
- Microsoft SQL Server 2019 Analysis Services
其他优秀软件
- Teradata Warehouse Miner
- IBM DB2 Intelligence Miner
Hadoop的核心
核心技术:
- 分布式文件系统
- 并行计算系统
分布式文件系统HDFS特点(Hadoop Distributed File System)

优点
处理超大文件:几百MB、几百TB的单个文件
流式的访问数据:一个数据源,多个存储节点;批量读取效率高
运行于廉价的商用机器集群上:易扩展;节点故障容错
缺点
不适合低延迟数据访问:服务于大型数据集分析;替代方案HBase
无法高效存储大量的小文件:每个小文件都分配Map任务,效率降低
不支持多用户写入及任意修改文件:一个写入者;只能追加;
运用的技术
- 存储块
将单个大文件切分成多个块:64MB or 128MB - NameNode/DataNode主从结构
分别负责目录和文件映射结构/实际数据块存储 - 心跳机制
NameNode判断DataNode状态 - 机架感知
感知每份数据块(备份3块)的位置
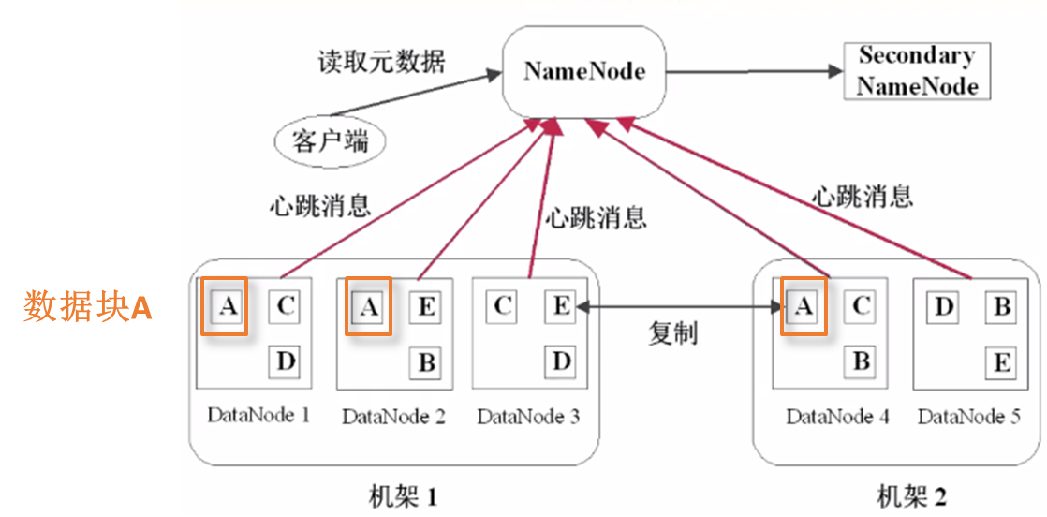
用户向namenode发起文件读取的请求,namenode用心跳机制感知datanode的状态,再用机架感知感知哪个数据块离客户端最近,将信息返回客户端,客户端再发起网络请求
