
环境
opencv-python 4.5.5.62
scipy 1.81
scikit-learn 1.0.2
torch 1.11.0
数据集 http://yann.lecun.com/exdb/mnist/
成果体验

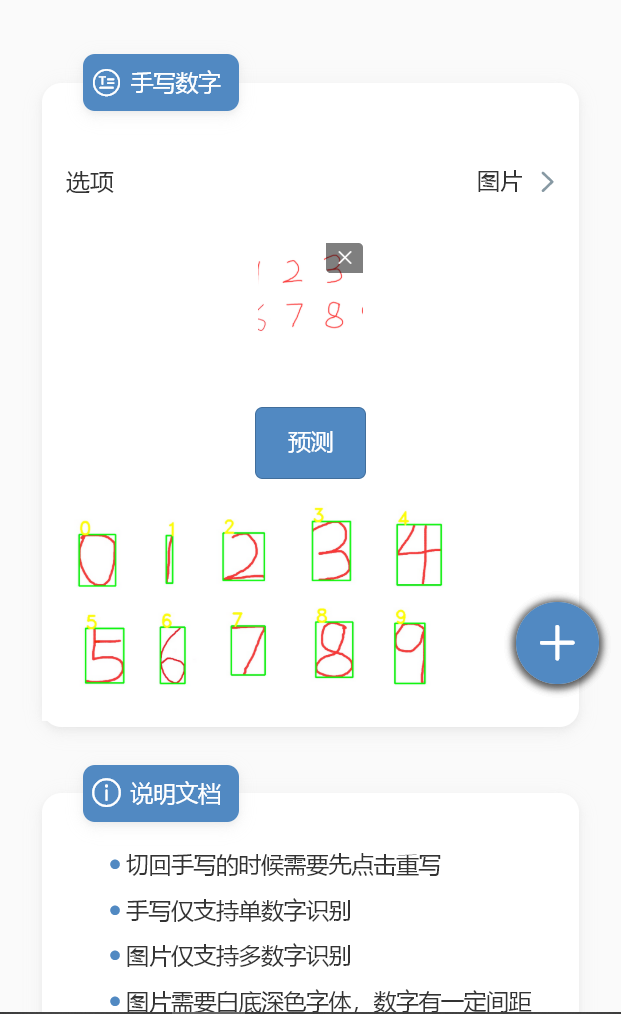

SVM
训练
from mlxtend.data import loadlocal_mnist
# 从本地加载数据集
train_img, train_label = loadlocal_mnist(
images_path='D:\data\mnist\\train-images.idx3-ubyte',
labels_path='D:\data\mnist\\train-labels.idx1-ubyte')
print("训练图片:",train_img,"训练数据格式:",train_img.shape)
print("训练标签",train_label,"训练标签格式:",train_label)
from skimage.feature import hog
import numpy as np
# 提取特征值
list_hog_ft = []
for feature in train_img:
ft = hog(feature.reshape((28, 28)), orientations=9, pixels_per_cell=(14, 14), cells_per_block=(1, 1), visualize=False)
list_hog_ft.append(ft)
hog_features = np.array(list_hog_ft, 'float64')
from sklearn import preprocessing
# 特征值归一化
pp = preprocessing.StandardScaler().fit(hog_features)
hog_features = pp.transform(hog_features)
print(hog_features.shape)
test_img, test_label = loadlocal_mnist(
images_path='D:\data\mnist\\t10k-images.idx3-ubyte',
labels_path='D:\data\mnist\\t10k-labels.idx1-ubyte')
print("训练图片:",test_img,"训练数据格式:",test_img.shape)
print("训练标签",test_label,"训练标签格式:",test_label)
list_hog_ft = []
for feature in test_img:
ft = hog(feature.reshape((28, 28)), orientations=9, pixels_per_cell=(14, 14), cells_per_block=(1, 1), visualize=False)
list_hog_ft.append(ft)
hog_features_test = np.array(list_hog_ft, 'float64')
pp = preprocessing.StandardScaler().fit(hog_features_test)
hog_features_test = pp.transform(hog_features_test)
print(hog_features_test.shape)
clf.score(hog_features_test, test_label)
# 保存模型
import joblib
# Save the classifier
joblib.dump((clf, pp), "D:\data\mnist\digits_cls1.pkl", compress=3)预测
import cv2
import joblib
from skimage.feature import hog
import numpy as np
from number_dis.model import model_path
modelPath = model_path('SVM.pkl')
class SVM_Predict:
def __init__(self):
self.clf, self.pp = joblib.load(modelPath)
def pre_nums(self, pic_path):
img, im_th, rects = self.get_num_recs(pic_path)
for rect in rects:
# Draw the rectangles
cv2.rectangle(img, (rect[0], rect[1]), (rect[0] + rect[2], rect[1] + rect[3]), (0, 255, 0), 3)
# 使数字周围的矩形区域
leng = int(rect[3] * 1.6)
pt1 = int(rect[1] + rect[3] // 2 - leng // 2)
pt2 = int(rect[0] + rect[2] // 2 - leng // 2)
roi = im_th[pt1:pt1 + leng, pt2:pt2 + leng]
# Resize the image
roi = cv2.resize(roi, (28, 28), interpolation=cv2.INTER_AREA)
roi = cv2.dilate(roi, (3, 3))
# 计算HOG特征
roi_hog_fd = hog(roi, orientations=9, pixels_per_cell=(14, 14), cells_per_block=(1, 1), visualize=False)
roi_hog_fd = self.pp.transform(np.array([roi_hog_fd], 'float64'))
# Pridict digit
nbr = self.clf.predict(roi_hog_fd)
cv2.putText(img, str(int(nbr[0])), (rect[0], rect[1]), cv2.FONT_HERSHEY_DUPLEX, 2, (0, 255, 255), 3)
return img
def get_num_recs(self, pic_path):
img = cv2.imread(pic_path)
# 灰度处理
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# (5, 5)表示高斯矩阵的长与宽都是5,标准差取0
img_gray = cv2.GaussianBlur(img_gray, (5, 5), 0)
# 图像的阈值
ret, im_th = cv2.threshold(img_gray, 120, 255, cv2.THRESH_BINARY_INV)
# 寻找图像中的轮廓线
ctrs, hier = cv2.findContours(im_th.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 获取包含每个轮廓的矩形
rects = [cv2.boundingRect(ctr) for ctr in ctrs]
return img, im_th, rects
if __name__ == '__main__':
img = SVM_Predict().pre_nums(model_path("demo.png"))
cv2.imwrite(model_path("demopre.png"), img)贝叶斯分类
训练
from PIL import Image
import numpy as np
import struct
import math
import matplotlib.pyplot as plt
from collections import Counter
from mlxtend.data import loadlocal_mnist
#二值化
def Binarization(images):
for i in range(images.shape[0]):
imageMean = images[i].mean()
images[i] = np.array([0 if x < imageMean else 1 for x in images[i]])
return images
#模型训练
def Bayes_train(train_x, train_y):
#先验概率P(0), P(1)....
totalNum = train_x.shape[0]
print(totalNum)
classNum = Counter(train_y)
print(classNum)
prioriP = np.array([classNum[i]/totalNum for i in range(10)])
print(prioriP,prioriP.shape)
#后验概率
posteriorNum = np.empty((10, train_x.shape[1]))
print(posteriorNum,posteriorNum.shape)
posteriorP = np.empty((10, train_x.shape[1]))
print(posteriorP,posteriorP.shape)
for i in range(10):
posteriorNum[i] = train_x[np.where(train_y == i)].sum(axis = 0)
#拉普拉斯平滑
posteriorP[i] = (posteriorNum[i] + 1) / (classNum[i] + 2)
print(posteriorNum,posteriorNum.shape)
print(posteriorP,posteriorP.shape)
return prioriP, posteriorP
#模型预测
def Bayes_pret(test_x, test_y, prioriP, posteriorP):
pret = np.empty(test_x.shape[0])
for i in range(test_x.shape[0]):
prob = np.empty(10)
for j in range(10):
temp = sum([math.log(1-posteriorP[j][x]) if test_x[i][x] == 0 else math.log(posteriorP[j][x]) for x in range(test_x.shape[1])])
prob[j] = np.array(math.log(prioriP[j]) + temp)
pret[i] = np.argmax(prob)
return pret, (pret == test_y).sum()/ test_y.shape[0]
train_img, train_y = loadlocal_mnist(
images_path='D:\data\mnist\\train-images.idx3-ubyte',
labels_path='D:\data\mnist\\train-labels.idx1-ubyte')
train_x_data = train_img.reshape(60000, 28, 28)
#train_x_data = decode_idx3_ubyte('D:/data/mnist/train-images.idx3-ubyte')
# train_x = imageResize(train_x)
#train_y = deconde_idx1_ubyte('D:/data/mnist/train-labels.idx1-ubyte')
#print(train_y.shape)
train_x = np.resize(train_x_data, (train_x_data.shape[0], train_x_data.shape[1]*train_x_data.shape[2]))
train_x = Binarization(train_x)
print(train_x.shape)
test_img, test_y = loadlocal_mnist(
images_path='D:\data\mnist\\t10k-images.idx3-ubyte',
labels_path='D:\data\mnist\\t10k-labels.idx1-ubyte')
test_x_data = test_img.reshape(10000, 28, 28)
#test_x_data = decode_idx3_ubyte('D:/data/mnist/t10k-images.idx3-ubyte')
#print(test_x_data.shape)
# test_x = imageResize(test_x)
#test_y = deconde_idx1_ubyte('D:/data/mnist/t10k-labels.idx1-ubyte')
#print(test_y.shape)
test_x = np.resize(test_x_data, (test_x_data.shape[0], test_x_data.shape[1]*test_x_data.shape[2]))
test_x = Binarization(test_x)
prioriP, posteriorP = Bayes_train(train_x, train_y)
accuracy = Bayes_pret(test_x, test_y, prioriP, posteriorP)
# 保存模型
import joblib
# Save the classifier
joblib.dump((prioriP, posteriorP), "D:\data\mnist\digits_cls1.pkl", compress=3)预测
import math
import cv2
import joblib
import numpy as np
from number_dis.model import model_path
modelPath = model_path('NB.pkl')
class NB_Predict:
def __init__(self):
self.prioriP, self.posteriorP = joblib.load(modelPath)
def pre_nums(self, pic_path):
img, im_th, rects = self.get_num_recs(pic_path)
for rect in rects:
# Draw the rectangles
cv2.rectangle(img, (rect[0], rect[1]), (rect[0] + rect[2], rect[1] + rect[3]), (0, 255, 0), 3)
# 使数字周围的矩形区域
leng = int(rect[3] * 1.6)
pt1 = int(rect[1] + rect[3] // 2 - leng // 2)
pt2 = int(rect[0] + rect[2] // 2 - leng // 2)
roi = im_th[pt1:pt1 + leng, pt2:pt2 + leng]
# Resize the image
roi = cv2.resize(roi, (28, 28), interpolation=cv2.INTER_AREA)
# print(roi,roi.shape)
test_x = np.resize(roi, (1, 28 * 28))
test_x = self.Binarization(test_x)
nbr = self.Bayes_pret(test_x, self.prioriP, self.posteriorP)
cv2.putText(img, str(int(nbr[0])), (rect[0], rect[1]), cv2.FONT_HERSHEY_DUPLEX, 2, (0, 255, 255), 3)
return img
def get_num_recs(self, pic_path):
img = cv2.imread(pic_path)
im_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
im_gray = cv2.GaussianBlur(im_gray, (5, 5), 0)
ret, im_th = cv2.threshold(im_gray, 120, 255, cv2.THRESH_BINARY_INV)
ctrs, hier = cv2.findContours(im_th.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
rects = [cv2.boundingRect(ctr) for ctr in ctrs]
return img, im_th, rects
# 二值化
def Binarization(self, images):
for i in range(images.shape[0]):
imageMean = images[i].mean()
images[i] = np.array([0 if x < imageMean else 1 for x in images[i]])
return images
def Bayes_pret(self, test_x, prioriP, posteriorP):
pret = np.empty(test_x.shape[0])
for i in range(test_x.shape[0]):
prob = np.empty(10)
for j in range(10):
temp = sum([math.log(1 - posteriorP[j][x]) if test_x[i][x] == 0 else math.log(posteriorP[j][x]) for x in
range(test_x.shape[1])])
prob[j] = np.array(math.log(prioriP[j]) + temp)
pret[i] = np.argmax(prob)
return pret
if __name__ == '__main__':
img = NB_Predict().pre_nums(model_path("demo.png"))
cv2.imwrite(model_path("demopre.png"), img)二叉树
训练
#二值化
def Binarization(images):
for i in range(images.shape[0]):
imageMean = images[i].mean()
images[i] = np.array([0 if x < imageMean else 1 for x in images[i]])
return images
from mlxtend.data import loadlocal_mnist
train_img, train_label = loadlocal_mnist(
images_path='D:\data\mnist\\train-images.idx3-ubyte',
labels_path='D:\data\mnist\\train-labels.idx1-ubyte')
print("训练图片:",train_img,"训练数据格式:",train_img.shape)
print("训练标签",train_label,"训练标签格式:",train_label.shape)
train_img = Binarization(train_img)
test_img, test_label = loadlocal_mnist(
images_path='D:\data\mnist\\t10k-images.idx3-ubyte',
labels_path='D:\data\mnist\\t10k-labels.idx1-ubyte')
print("训练图片:",test_img[0],"训练数据格式:",test_img.shape)
print("训练标签",test_label,"训练标签格式:",test_label.shape)
test_img = Binarization(test_img)
# 建模和机器学习
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix,accuracy_score, classification_report
from sklearn.model_selection import train_test_split
dtModel = DecisionTreeClassifier() # 建立模型
dtModel.fit(train_img,train_label)
prediction = dtModel.predict(test_img)
acc = accuracy_score(test_label,prediction)
print(f"Sum Axis-1 as Classification accuracy: {acc* 100}")
prediction = dtModel.predict([test_img[0]])预测
import cv2
import joblib
import numpy as np
from number_dis.model import model_path
modelPath = model_path('DecisionTree.pkl')
class Tree_Predict:
def __init__(self):
self.model = joblib.load(modelPath)
def pre_nums(self, pic_path):
img, im_th, rects = self.get_num_recs(pic_path)
for rect in rects:
# Draw the rectangles
cv2.rectangle(img, (rect[0], rect[1]), (rect[0] + rect[2], rect[1] + rect[3]), (0, 255, 0), 3)
# 使数字周围的矩形区域
leng = int(rect[3] * 1.6)
pt1 = int(rect[1] + rect[3] // 2 - leng // 2)
pt2 = int(rect[0] + rect[2] // 2 - leng // 2)
roi = im_th[pt1:pt1 + leng, pt2:pt2 + leng]
roi = cv2.resize(roi, (28, 28), interpolation=cv2.INTER_AREA)
test_x = np.resize(roi, (1, 28 * 28))
test_x = self.Binarization(test_x)
result = self.model.predict(test_x)
cv2.putText(img, str(int(result[0])), (rect[0], rect[1]), cv2.FONT_HERSHEY_DUPLEX, 2, (0, 255, 255), 3)
return img
def get_num_recs(self, pic_path):
img = cv2.imread(pic_path)
# 灰度处理
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# (5, 5)表示高斯矩阵的长与宽都是5,标准差取0
img_gray = cv2.GaussianBlur(img_gray, (5, 5), 0)
# 图像的阈值
ret, im_th = cv2.threshold(img_gray, 120, 255, cv2.THRESH_BINARY_INV)
# 寻找图像中的轮廓线
ctrs, hier = cv2.findContours(im_th.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 获取包含每个轮廓的矩形
rects = [cv2.boundingRect(ctr) for ctr in ctrs]
return img, im_th, rects
# 二值化
def Binarization(self, images):
for i in range(images.shape[0]):
imageMean = images[i].mean()
images[i] = np.array([0 if x < imageMean else 1 for x in images[i]])
return imagesCNN
训练用的GPU,预测用的CPU
训练
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 检测是否有GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
EPOCH = 10
BATCH_SIZE = 128
LR = 1E-3
# 读取数据集,transforms.ToTensor()将PIL格式的图像以及numpy转化为tensor格式
train_file = datasets.MNIST(
root='D:\data\mnist\data',
train=True,
transform=transforms.ToTensor(),
download=True
)
test_file = datasets.MNIST(
root='D:\data\mnist\data',
train=False,
transform=transforms.ToTensor()
)
# shuffle = True:是否打乱数据
train_loader = DataLoader(
dataset=train_file,
batch_size=BATCH_SIZE,
shuffle=True
)
test_loader = DataLoader(
dataset=test_file,
batch_size=BATCH_SIZE,
shuffle=False
)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv = nn.Sequential(
# 参数1:输入通道数,黑白为1,彩色为3
# 参数2:输出通道数,生成32个特征图
# 参数3:卷积窗口 5*5
# 参数4: 步长1
# 参数5: 补两圈0,(3*3补充一圈0)
nn.Conv2d(1, 32, 5, 1, 2),
# 小于0为0,大于0不变
nn.ReLU(),
# 最大池化的窗口大小
nn.MaxPool2d(2),
# [BATCH_SIZE, 32, 14, 14]
nn.Conv2d(32, 64, 5, 1, 2),
# [BATCH_SIZE, 64, 14, 14]
nn.ReLU(),
nn.MaxPool2d(2)
# [BATCH_SIZE, 64, 7, 7]
)
self.fc = nn.Linear(64 * 7 * 7, 10)
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
y = self.fc(x)
return y
model = CNN().to(device)
# 优化器
optim = torch.optim.Adam(model.parameters(), LR)
# 损失函数
lossf = nn.CrossEntropyLoss()
import time
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('D:\data\mnist\logs')
#%% 定义计算整个训练集或测试集loss及acc的函数
def calc(data_loader):
loss = 0
total = 0
correct = 0
with torch.no_grad():
for data, targets in data_loader:
data = data.to(device)
targets = targets.to(device)
output = model(data)
loss += lossf(output, targets)
correct += (output.argmax(1) == targets).sum()
total += data.size(0)
loss = loss.item()/len(data_loader)
acc = correct.item()/total
return loss, acc
#%% 训练过程打印函数
def show():
# 定义全局变量
if epoch == 0:
global model_saved_list
global temp
temp = 0
# 打印训练的EPOCH和STEP信息
header_list = [
f'EPOCH: {epoch+1:0>{len(str(EPOCH))}}/{EPOCH}',
f'STEP: {step+1:0>{len(str(len(train_loader)))}}/{len(train_loader)}'
]
header_show = ' '.join(header_list)
print(header_show, end=' ')
# 打印训练的LOSS和ACC信息
loss, acc = calc(train_loader)
writer.add_scalar('loss', loss, epoch+1)
writer.add_scalar('acc', acc, epoch+1)
train_list = [
f'LOSS: {loss:.4f}',
f'ACC: {acc:.4f}'
]
train_show = ' '.join(train_list)
print(train_show, end=' ')
# 打印测试的LOSS和ACC信息
val_loss, val_acc = calc(test_loader)
writer.add_scalar('val_loss', val_loss, epoch+1)
writer.add_scalar('val_acc', val_acc, epoch+1)
test_list = [
f'VAL-LOSS: {val_loss:.4f}',
f'VAL-ACC: {val_acc:.4f}'
]
test_show = ' '.join(test_list)
print(test_show, end=' ')
# 保存最佳模型
if val_acc > temp:
model_saved_list = header_list+train_list+test_list
torch.save(model.state_dict(), 'model.pt')
temp = val_acc
#%% 训练模型
for epoch in range(EPOCH):
start_time = time.time()
for step, (data, targets) in enumerate(train_loader):
# 梯度信息置零
optim.zero_grad()
data = data.to(device)
targets = targets.to(device)
output = model(data)
loss = lossf(output, targets)
acc = (output.argmax(1) == targets).sum().item()/BATCH_SIZE
loss.backward()
optim.step()
print(
f'EPOCH: {epoch+1:0>{len(str(EPOCH))}}/{EPOCH}',
f'STEP: {step+1:0>{len(str(len(train_loader)))}}/{len(train_loader)}',
f'LOSS: {loss.item():.4f}',
f'ACC: {acc:.4f}',
end='\r'
)
show()
end_time = time.time()
print(f'TOTAL-TIME: {round(end_time-start_time)}')预测
import base64
import cv2
import torch
import torch.nn as nn
import numpy as np
from torchvision import transforms
from service.v3.number_dis.model import model_path
# 检测是否有GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
modelPath = model_path('CNN.pt')
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv = nn.Sequential(
# 参数1:输入通道数,黑白为1,彩色为3
# 参数2:输出通道数,生成32个特征图
# 参数3:卷积窗口 5*5
# 参数4: 步长1
# 参数5: 补两圈0,(3*3补充一圈0)
nn.Conv2d(1, 32, 5, 1, 2),
# 小于0为0,大于0不变
nn.ReLU(),
# 最大池化的窗口大小
nn.MaxPool2d(2),
# [BATCH_SIZE, 32, 14, 14]
nn.Conv2d(32, 64, 5, 1, 2),
# [BATCH_SIZE, 64, 14, 14]
nn.ReLU(),
nn.MaxPool2d(2)
# [BATCH_SIZE, 64, 7, 7]
)
self.fc = nn.Linear(64 * 7 * 7, 10)
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
y = self.fc(x)
return y
class CNN_Predict:
def __init__(self):
self.model = CNN()
self.model.load_state_dict(torch.load(modelPath, map_location=torch.device(device)))
# 评估模式
self.model.eval()
def transform_pic(self, img):
my_transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(28),
transforms.Grayscale(),
transforms.ToTensor()
])
return my_transforms(img)
def pre_nums(self, pic_path):
img, im_th, rects = self.get_num_recs(pic_path)
for rect in rects:
cv2.rectangle(img, (rect[0], rect[1]), (rect[0] + rect[2], rect[1] + rect[3]), (0, 255, 0), 3)
leng = int(rect[3] * 1.6)
pt1 = int(rect[1] + rect[3] // 2 - leng // 2)
pt2 = int(rect[0] + rect[2] // 2 - leng // 2)
roi = im_th[pt1:pt1 + leng, pt2:pt2 + leng]
roi = cv2.resize(roi, (28, 28), interpolation=cv2.INTER_AREA)
with torch.no_grad():
data = self.transform_pic(roi)
data_pre = data.to(device)
data_pre = data_pre.unsqueeze(0)
result = self.model(data_pre).argmax(1).item()
cv2.putText(img, str(int(result)), (rect[0], rect[1]), cv2.FONT_HERSHEY_DUPLEX, 2, (0, 255, 255), 3)
return img
def pre_num(self, pic_path):
pic_path = pic_path.split("base64,")[1]
image_data = base64.b64decode(pic_path)
image_array = np.frombuffer(image_data, np.uint8)
img = cv2.imdecode(image_array, cv2.IMREAD_COLOR)
im_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
im_gray = cv2.GaussianBlur(im_gray, (5, 5), 0)
ret, im_th = cv2.threshold(im_gray, 120, 255, cv2.THRESH_BINARY_INV)
with torch.no_grad():
data = self.transform_pic(im_th)
data_pre = data.to(device)
data_pre = data_pre.unsqueeze(0)
result = self.model(data_pre).argmax(1).item()
return result
def get_num_recs(self, pic_path):
img = cv2.imread(pic_path)
im_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
im_gray = cv2.GaussianBlur(im_gray, (5, 5), 0)
ret, im_th = cv2.threshold(im_gray, 120, 255, cv2.THRESH_BINARY_INV)
ctrs, hier = cv2.findContours(im_th.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
rects = [cv2.boundingRect(ctr) for ctr in ctrs]
return img, im_th, rects
if __name__ == '__main__':
img = CNN_Predict().pre_nums(model_path("demo.png"))
cv2.imwrite(model_path("demopre.jpg"), img)参考
https://blog.csdn.net/qq_44977889/article/details/119353366
https://blog.csdn.net/qwe900/article/details/110189207
https://www.freesion.com/article/2957960288/
https://blog.csdn.net/QRDSHU/article/details/123832876
https://blog.csdn.net/m0_37306360/article/details/79311501
https://blog.csdn.net/qq_42951560/article/details/109565625

One comment
温柔帅气的大哥哥